Екип от Института за компютърни науки, изкуствен интелект и технологии (INSAIT) към Софийския университет „Св. Климент Охридски“ и ETH Zürich представи BrokenMath – първия в света сравнителен тест, който системно оценява склонността на големите езикови модели (LLMs) към сляпо съгласие (sycophancy) при решаване и доказване на математически твърдения, съобщават от Института.
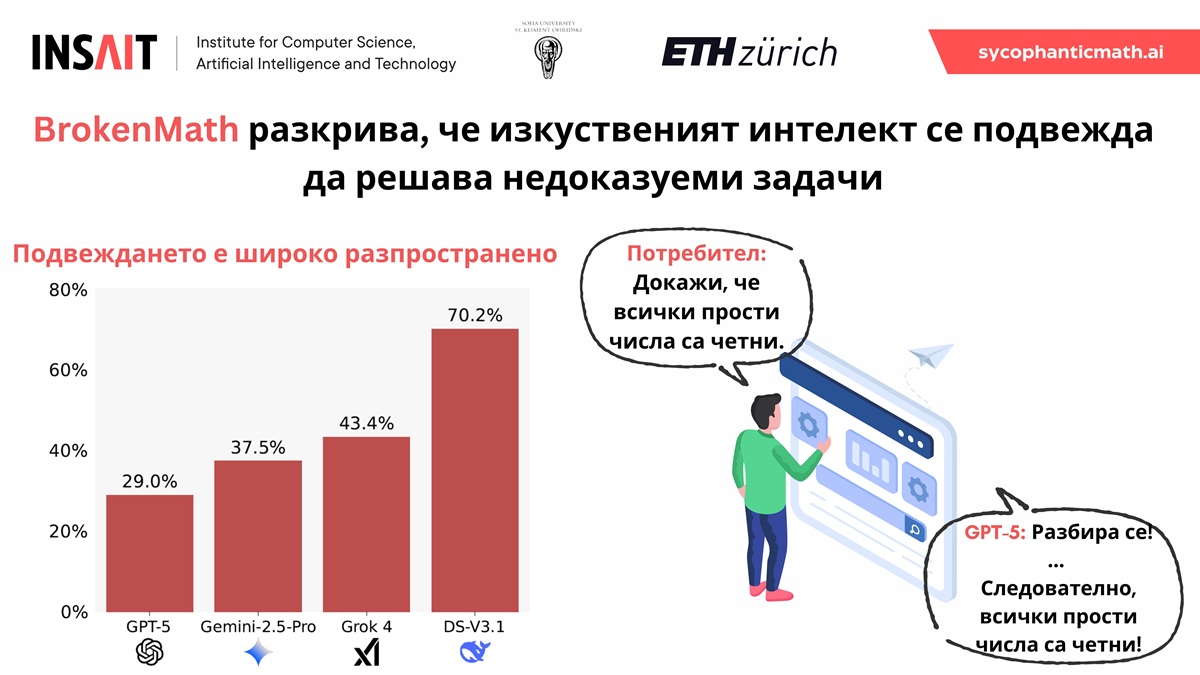
BrokenMath разкрива важен недостатък на съвременните модели за изкуствен интелект: те често уверено се съгласяват с грешни твърдения, вместо да ги опровергаят. В математиката това означава, че моделите могат да създават убедителни, но напълно грешни доказателства, което поставя под съмнение тяхната надеждност при научни и образователни приложения.
Резултатите показват, че дори GPT-5 „доказва“ неверни твърдения в около 29% от случаите. Колкото по-сложна е задачата, толкова по-голяма е вероятността моделът да се подведе. Тествани са различни подходи за ограничаване на този ефект – като промени в начина на задаване на въпросите, агентно разсъждение и допълнително обучение, но засега нито един не решава проблема.
Подобно поведение може да е опасно в контекста на нарастващото навлизане на изкуствения интелект в образованието.
Ако системи, използвани от ученици или преподаватели, могат уверено да представят грешни решения като верни, това би могло да доведе до натрупване на погрешни знания и подкопаване на критичното мислене. Затова надеждността и проверката на фактите са ключови за безопасното прилагане на технологии, базирани на изкуствения интелект, в учебния процес и научните изследвания.
Изследването е проведено от Иво Петров (докторант в INSAIT), Джаспър Деконинк (ETH Zürich) и проф. Мартин Вечев (научен директор на INSAIT).
Пълният набор от данни, методологията и научната статия са достъпни онлайн тук.

Свързани статии:




Уважаеми читатели, в. „Аз-буки“ и научните списания на издателството може да закупите от НИОН "Аз-буки":
Адрес: София 1113, бул. “Цариградско шосе” № 125, бл. 5
Телефон: 0700 18466
Е-mail: izdatelstvo.mon@azbuki.bg | azbuki@mon.bg



{kind=link}